Realtime Procedural Audio and Synthesized Piano in Unity 3D
An introduction to mathematically generate the sound waveforms and create any sound you wish with endless variations

This post will cover how to generate sounds procedurally — by constructing the waveforms mathematically, using sinus waves — in Unity 3D and C#. The end goal is to synthesize a procedural piano, which you can play using the keyboard. The program can also read a digitalized music sheet and play it for you!
Generating the sounds procedurally for your game has many of the advantages which procedural textures offer: You can add endless variations to sounds like engine noises, clicks or bullets; Make the sound properties reactive to the player behavior and generate sounds for elements you don’t or can’t have recordings for.
As usual you will find the code on my Github:
https://github.com/IRCSS/Procedural-Sound
The article is structured like this:
- How does the speaker generate sounds
- Programming the speaker cone
- Implementation details in Unity
- Creating musical notes
- Final thoughts and further improvements
- Further Readings
How Does The Speaker Generate Sounds
Generating sounds procedurally requires you to have a top level understanding of how a speaker generates sounds! Whatever I say here is an extreme over simplification. If you are interested to know more, I suggest reading more on the topic.
Imagine you have a plate which can be moved up and down. Moving this surface up and down will push the air particles around that surface out of their resting position. Those particle which have been displaced, push the particles around them out of their resting position too. This phenomena will propagate through the air, as each particle displaces their neighboring air particles.
This propagation is actually in the form of a single wave peak. Since there is a certain elasticity to these particles, they wish to go back to their resting position, which is zero displacement. After the wave front has passed, the particles have gone from the zero displacement, to max and to zero again. In the real world, they will over shoot zero displacement and oscillate around it, but we will ignore that for now.
Now we can place a thin surface, which is allowed to vibrate, a few meters away from our moving plate. Once the wave front reaches the thin membrane, it will cause it to also go through the same displacement. This displacement mirrors the original displacement of our moving plate. So we have successfully sent a signal through space from a source to a receiver. If this membrane is somehow hooked up to a sensory system that can measure the amount of displacement happening, we have even communicated some information, specifically how far the original source — the moving plate — has been displaced. I am going to commit an over the top simplification, and call this thin membrane and the black box sensory system attached to it the human ear and the original moving plate the speaker cone.
Of course the moving plate doesn’t have to move just for a single instance, it can carry on moving back and forth as it wishes. This will create a series of waves, which will reach the human ear.
These waves are not necessarily Sounds, just in the same way all electro magnetic waves are not colors! Which you can read more about in my Introduction to Color Theory for Games, Art and Tech.
In order for us to perceive them as sounds, the speaker cone needs to be moving back and forth fast enough. Let’s assume that the movement of the cone is periodic — meaning it repeats itself exactly as time goes on, just like the visual example provided. Then we can look at how many cycles the wave goes through per second. A cycle is when the cone has gone from maximum displacement, to minimum and back to maximum displacement again. The number of cycles per second is the frequency of the wave, measured in Hertz (Hz).
The human ears can hear between 20 Hz to 20,000 Hz. Most adults however can hear up to 15k Hz. How high you can hear you can test for yourself in the application later.
In higher frequencies the speaker cone will be moving so fast that you can’t see its movement anymore.
Before we get to how to program the speaker, it is worth mentioning the difference between periodic and aperiodic sounds. The speaker doesn’t have to move in a periodic pattern. It can also chaotically move back and forth. If it does move periodically, you would hear a tone! If it doesn’t you would hear noise. Musical instruments usually create dominantly periodic sounds and things like waterfalls, ocean waves or clicks create aperiodic sounds! Most sound sources however have both inside, periodic and aperiodic parts overlapping. You also need both for creating procedural sounds for your game!
Programming The Speaker Cone
The speaker cone has one parameter which is changing over time, its displacement along its forward axis. In a normal audio recording, there would be an array of float values representing where the speaker cone should be as time goes on. An application would open an audio file, read this float array and provide it to the speaker driver. Given that, surely we can generate the values in this array procedurally and generate whatever sound we want.
To start with we can simply hook up the displacement of the cone to a periodic mathematical function. I am going to take the sinus wave. So the function is sin(time), where time is the application time.
A normal sin(time) however has a period of 2π. The period is inversely proportional to the frequency (period = 1/frequency). That means it has a frequency of 0.1592 Hz (1/2π). Since this is lower than minimum range of perceivable sounds, you won’t hear a sound! You need to first normalize the sin to have a period of 1 then multiply with 1/Period or the Frequency to get your desired frequency.
Speaker Cone Displacement = sin(time* 2π *frequency)
Or
float waveFunction(time, frequency)
{
return sin(time* 2π *frequency);
}At this point you should hear a perfect pure tone! This is not something you would hear in nature as sounds are not made out of a single wave, but many different ones overlapping each other. However it is the easiest procedural sound you can make!
Implementation Details in Unity
How do you implement the above in Unity? Can you just supply the speaker’s driver with a sinus function and call it a day? For many different reasons — which I won’t get into — the information is provided as a series of samples instead of series of wave functions.
A sample is the position of the speaker cone at a given time. In our case of a standard sinus function, we can easily approximate the function by taking a given number of samples. For example, let’s assume we take 13 samples:


Then the speaker can go over these samples and for any given time find the correct position of the speaker cone by interpolating between the two closes samples to the time it is at.
So how many samples does the speaker need per seconds? This depends on your settings and speaker. More samples is of course better as you can reconstruct the original wave better. However more samples also means more memory and performance cost!
An important thing to consider is that depending on how high you want your frequency to be, you would need a minimum amount of samples. This has a simple reason. Let’s say your wave goes through a cycle every second and you take a sample every two seconds. Since two entire cycles go through between your samples, which the speaker can’t possibly know about, it can not correctly reconstruct the original wave!


In order to be able to correctly reproduce the periodic nature of a wave, you would need at least twice as many samples as its frequency. So if you want to generate 20k Hz sounds, you would need 40,000 samples per second!
Here is issue number one. You usually update your game between 30 to 60 times per seconds (30–60 fps). How are you supposed to provide the speaker with 40k values per second? Since 40k frames per seconds is very unrealistic and completely unnecessarily, programs provide a bunch of the sample values together in an array to the speaker at pre determined intervals.
If there was no interactivity, you could precalculate a giant array of samples, send it to the speaker and call it a day. But in games and applications, you usually need interactive sounds, for example by pressing a button, a sound is played. These sounds can have some latency however, if you press a button and it takes the speaker 20 milliseconds to get the information about how the waveforms have changed, it is absolutely fine.
For this reason there is a separate audio thread in Unity (like most applications), which provides the samples array every once in a while. This array contains all the samples required until the next time the thread is called to update the array.
There are a few ways in Unity to provide an array of samples of your own. I suggest OnAudioFilterRead. You need to define this function in a C# script attached as a component to a game object which has an AudioSource. What OnRenderImage does for graphics, this function does for sound. At some point the data already generated by the audio source is passed to this function as an array of floats. You can modify/ overwrite this array however you wish.
It is important to mention that this is on a different thread. While it might not look like it, the update function you write right below this function will be called at a different cadence.
OnAudioFilterRead is called whenever the audio stream info is updated. Per default this is every 0.02133… seconds or ca. 47 fps.
How many samples you need per second is defined by your sample rate. The default sample rate in Unity is 48k. For the given 47 frame rate, you would need to supply the speaker with 1024 samples every time this function is called.
However if you print the length of the data[] array provided by the function as input, you might be surprised that it contains 1024*2 samples. This is because the array needs to hold 1024 samples per channel! If your audioSource is set as stereo, you would have a channel for left and right ear. The function argument int channels provides this information as input. So the number of samples you need to provide is data.length/channels.
Last point to keep in mind regarding this array, due to cache locality reasons, the samples of different channels are saved right next to each other. So the array has a structure like this:

Now it is time to populate the array with samples taken from our waveFunction(time, frequency). Remember that each of these 1024 samples represent the position of the cone at a different time. So we need to calculate the correct time value for each sample first.
If your sampler rate is 48k times per second, that means the time duration between each sample is 1/48k seconds. This is very easy to check. The 1024 samples in the data[] array need to provide the speaker with enough information to cover the entire frame duration. That means 1024 * 1/48k = 0.021333… should equal the frame time of our audio thread, which it does.
When you are looping over your data array to populate it, the sample time is the current thread time (when the OnAudioFilterRead is called and this array is being populated) plus the index of the sample * 1/48k. This is basically projecting the time in to the future and calculating what value the wave displacement would have at that specific time.
for(int i = 0; i<data[].length; i = i +2)
{
data[i] = waveFunction(currentThreadTime + i/sampleRate, freque)
data[i+1] = data[i];
}In the above pseudo code, I am simply copying over the audio from the left to the right ear. This might as well be a Mono stream. Also the code assumes there are exactly 2 channels. You can write a more general case like this:
for(int i = 0; i<data[].length; i = i + channels)
{
data[i] = waveFunction(currentThreadTime + i/sampleRate, freque)
for(int j = 1; j<channels; j++)
{
data[i+j] = data[i];
}
}So we are done right?
Floating Point Accuracy Issues
For those of you who also write shaders, you might already know that, if you pass on the game Time to your procedural noise functions to generate procedural visuals, after a long time some really weird stuff can happen. This is due to accuracy issues that pop up when a float gets too large and it is used in a context where small variation are still of great importance. Let’s see how that applies to our case!
A sound that has a frequency of 10k Hz, has a period of 0.0001 seconds. We already said that you need twice as many samples as the frequency, so every 0.00005 seconds a new sample needs to be generated. What does this have to do with floating points?
A float in C# is 4 bytes, which gives you around 6–9 digits of precision. In my experience above 6 digits you already start seeing issues. If your game has been running for a minute, your frame time is already 60.0000 seconds. You need to provide a sample at 60.0000, 60.00005, 60.0001, 60.00015 etc. in order to successfully generate a 10k Hz sound. The crucial point is that your minimum required sampling range is already beyond 6 digits in the trouble zone! That means the waveFunction(time, frequency) will not give you precise/ correct values for the times mentioned above. This problem gets even worse if your game has been running for 20 minutes!
If you code the above, you would hear a weird noise accompanied with some tonal sound, depending on which frequency you wish to create and how large the time is.
For this very reason the time provided by the audio thread is measured in Doubles, instead of the Floats which Time.time is measured in. This is the AudioSettings.dspTime. However all utility functions and classes in Unity (such as fMath) require you to turn this value to a float at some point. The question is when, and how!
Keeping Track of The Phase
One way to deal with this problem is to keep track of the phase of the wave as it completes its cycle. This phase parameter will keep track of how far we are at a given time in the periodic cycle of a wave.
It goes between 0 and 2π. At 2π we can reset the phase parameter back to zero due to the periodic nature of the wave. Like this we don’t have to worry about the floating point issue since with the largest value the phase parameter can take (2π), the minimum sample rate we need for 20k Hz is still within the 6 digits.
In code, it will look like this:
float increment = (frequency * 2π) / sampleRate
for(int i = 0; i<data[].length; i = i + channels)
{
phase += increment;
if(phase>2π) phase = 0;
data[i] = sin(phase)
for(int j = 1; j<channels; j++)
{
data[i+j] = data[i];
}
}We want to increment our phase by 1/sampleRate every time a sample is taken, because that is how much time goes by between each sample. Beside that you should already be familiar with the frequency*2π calculation, which kind of normalizes the standard sinus so that its period equals 1/frequency.
This is one way to go around the problem. You can use this code and it will work just fine. It is important to mention that different frequencies should have different phases parameter. Even the same frequency might be out of phase and require a separate phase parameter. All in all you need a unique phase parameter for each sinus wave you want to add to your procedural sound.
You can modulate the frequency of an already existing wave. You just need to be careful with how you do that, and offset the phase so that there is no inconsistency in the frequency domain. Increasing/ decreasing the period over time will cause you to hear to many different frequencies in a short period of time, which characteristically is close to white noise or impulse sound (like a click).
Modulo as Alternative
The dspTime which Unity provides the audio thread with is a double as mentioned. If you convert the time properly to a float for calculations, you can get away with generating your desired tone without having to keep a phase float parameter for every single wave you need to add to your procedural sound.
One way of doing this is to use the Modulo operator (%). The modulo operator gives you the remainder after a division. So if you took the total time divided by the period of your wave, the remainder correlates with the phase of the function. The exact relationship is:
phase =(float)(totalTime %(1.0/(double)frequency)) * frequency * 2π;In our case with the data[] array we need to also take into account that the samples represent different times. To minimize the precision problem it is best to add that to the phase after casting to a float:
phase =(float)(totalTime %(1.0/(double)frequency));
phase = (phase + i/sampleRate) * frequency * 2π;
data[i] = Mathf.Sin(phase);Like this you won’t have to keep track of a bunch of phase values (which you can do if you want to, there is nothing technically challenging about that). Since I wanted to overlap a lot of waves, I decided to go with this workflow.
Creating Musical Notes
You almost have a real life instrument! You can play different frequencies which correlate to different musical notes. The only problem is that musical instruments never generate a single wave but many different waves overlapping each other!
I will cover the theory briefly and you should google whatever you are still curious about.
When you pluck a guitar string — the B-string for example — you don’t create a perfect arc before you release the string. This means that different points of the string will reach the center point at different times, overshooting it at different times and start oscillating at different frequencies. So the string will oscillate not only in a single frequency but many different frequencies simultaneously. There will be a single frequency which will be the loudest to our auditory senses called the fundamental frequency. All the other frequencies accompanying it are called the overtones.
In the case of a guitar the string is bound on both ends. This means the only frequencies that can exist in it are those where the displacement at the end of the guitar strings are always zero. Any moving waves which will require the guitar string to move on those spots will meet a very strong resistance which will dissipate the wave energy to heat. This is not the only or the most accurate way of explaining the phenomena but the short version is, an ideal guitar string can only oscillate in frequencies that are direct incrementation of the fundamental frequencies. It can oscillate at the fundamental frequency, 2 times fundamental frequency, 3 times fundamental frequency etc.

The above series is called a harmonic series. Overtones like these would be called the harmonics overtones. Real life is not the ideal guitar string however. The guitar does produce other frequencies as well, it just peaks at certain frequencies close to the harmonic series. Any over tone that is not compliance to the harmonic series is inharmonic. Some instruments like the piano for example create more inharmonic overtones than the guitar.
Different overtones are the reason why different instruments sound different. Even within the same instrument a key on the left side of the piano would have different composition of overtones than the one on the right. A general tendency is that the overtones lose in volume pretty fast the further away they get from the fundamental frequency and lower frequencies usually generate louder over tones — hence the keys on the left side of the piano sound so deep and rich!
The theory mentioned above should be enough for us to generate a note that sounds more like something played by a piano!
Notes With Harmonics
Generating harmonics along your fundamental frequency is actually quite trivial. To simulate the overlapping or superimposing which happens between different frequencies when you play a note, you can add a bunch of sinus waves together with different frequencies.
data[i] = waveFunction(time, fundementalFrequency ) +
waveFunction(time, fundementalFrequency * 2.0f);In my case I decided to ignore all the inharmonic overtones for simplicity and only focus on the first 12 harmonics. I have a harmonicStrengths array which determines how loud each harmonic is in relation to the fundamental frequency. Playing around with this will make the note sound like they are being played by different instruments.

We can still only play a single frequency at the same time though, and this frequency plays all the time at constant volume, unlike an actual instrument.
Note Envelopes and Playing Several Notes Simultaneously
When you play a note on the piano the sound doesn’t go on indefinitely. After the string is hammered it pretty immediately reaches maximum loudness and slowly decades away. You can shorten the decaying phase by letting go of the key you played which brings in the pianos damping system that stops the string from vibrating. How long a note is supposed to be held is determined by the music sheet!
You would need to emulate all that in order to make your tone sound like a piano. Although all frequencies of different sound sources merge together and superimpose, our brain decouples them all from another and hears each sound made as an event of its own. If you play C and the B, the brain keeps track of each sound’s progression as a separate event. When thinking about these sound events it is useful to describe how the volume of the sound changes across its life time. A popular model or envelope is the ADSR system. This describes how long it takes for the sound to reach its max volume (Attack), how long until it Decays down from the maximum to a stable Sustained level, and finally how long until it takes for the sound to Release and disappear to zero volume.
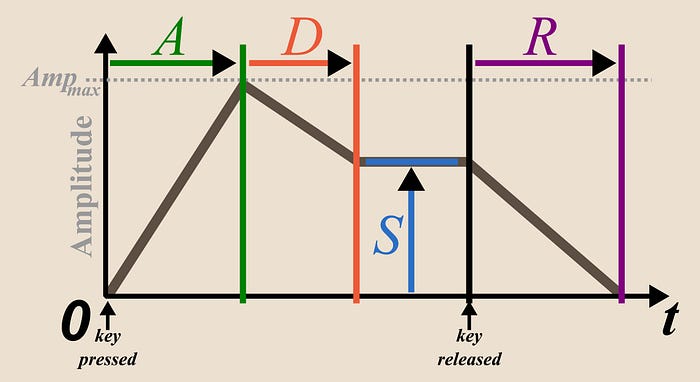
So there are two things we still need to program. First an interface for ADSR envelope, second a system where we can have several notes playing at the same time.
In a general case where you need to be able to emulate any given frequency, with an unknown number of overlapping sound events, designing an audio input system can become quite challenging. You would need something like an append/ consume buffer where you can append new sound events as a struct of a sort, saving all relevant information such as the wave frequency, over tones composition, ADSR information etc.
Then in your update, you take these events structs and you process them. You look at how much time has gone by since beginning of the sound event and determine how much they contribute to your sound waveform for any given sample. Then if your sound still hasn’t died down and should contribute to the next frame as well, you append it to your append buffer to be reprocessed again the next frame.
In our piano example however, we don’t have to do all that. The biggest piano only has 108 keys at discrete frequencies and grand pianos only have 88 keys. We will simply create an array 108 keys long with one entry for every note. The first key will be C0 (16.35 Hz) in scientific pitch terms and the highest B8 (7902.14). The array is made out of the ActiveNote struct, which holds all relevant information we need to process the sound in our game loop.

Then if a piano key is pressed or released, we simply need to update this array accordingly:
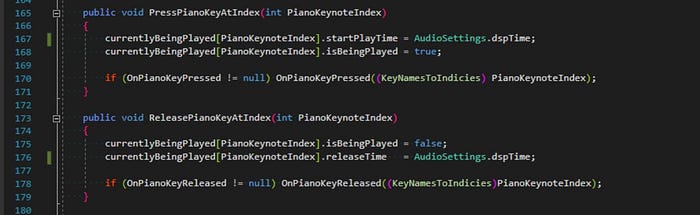
Now we have all the information we need to process our procedural sound waveform per frame. We will simply iterate over this array and for every key determine whether that piano key sound event should contribute to our over all sound for that frame. This is based on whether the key is being actively pressed down at the moment and where in the ADSR envelope process it is. As mentioned before, all the harmonics over tones are simply calculated from the fundamental frequency:

That was it! You have now a working piano. There are a million things you can improve and several other things I have done in the repo which I will cover very briefly.
Final Thoughts
Playing a Piece
The repo has a bunch of classes which can play a musical piece. The Pianist class takes in a MusicSheet instance and a beat per minute (tempo) and plays that sheet by using the press and release key API of the piano class we wrote above!
The pianist has two hands, left and right. One plays the Treble and the other the Bass Staffs. You can play around with this class by changing the beats per minute or enabling/ disabling the left or write hand. Also using the class you can play some notes yourself by using the keys specified in the Notes Key Codes array!
I won’t go into much detail regarding how the Pianist is implemented, because it is trivial. It simply parses the Music Sheet class, which is a data container holding a digitalized music sheet. The music sheet class is made out of Staffs (Trable and Bass in this case) and the time signature of the piece (beats per measure and note value of a single beat).

The staff itself has a KeyScale identifier — important to know which notes are flats/sharps — and is made out of a number of measures. The measures have the notes inside. Each note has a composition like this:

You would need to have some surface level understanding of how to read a music sheet, but if you do, hopefully the system is self explanatory!
Visualizer
The visualizer contains an actual piano and representation for the wave form. In the demo I am zooming in the waveform for better legibility. Both are done using shaders. On update whenever the sound form has changed or a new key has been pressed/ released, I update a structured buffer containing all the nessecerly information and then procedurally draw it in a shader.
The process of drawing a procedural piano and highlighting the keys that are being pressed is not exactly simple, but since it is kind of irrelevant to this article, I won’t be covering it!

Further Improvements
Here are some stuff worth improving if you want to continue with a instrument synthesizer.
Inharmonic Overtones: As I mentioned before many musical instruments also have inharmonics overtone. You can use the same architecture (predetermined resolution for the overtones) to calculate the contribution of all the overtones at discrete steps. If you think about it, the problem is actually similar to what rasterization is trying to solve! The main difference is that our perception of frequency is not linear. 5 hz difference in the lower frequency is a difference between two different notes where has the same difference in higher frequency is not noticeable.
Everything in GPU: Just like how rasterization discretizes 3D shapes, you can set up something similar over the frequency domain for the sound. Using the parallel processing powers of the GPU and compute shaders, you can get a lot more complicated sounds in real time.
ADSR settings per overtone: Overtones don’t all have the same envelope. The fundamental frequency lingers on longer than the higher over tones and there is variation in the Release times within the overtones themselves. Again you can easily model this in the application. If not for every single 108 keys, you can define it for a few and interpolate between those settings for the in-between keys.
Per Key overtone Strength: At the moment all keys have the same overtone composition. However the lower notes produce lowered overtones. You can implement this similar to the above point.
Compensating for the Equal loudness Contour: The human auditory sensory system is optimized for a certain range of frequencies, around where human voice and most common relevant sounds are. That means to hear a deeper note at the same level of perceived loudness as a mid range note, the deeper needs to be louder. How louder exactly can be modeled based on these curves derived from lab experiments.
More human-like playing: There is a machine precision in how the code plays the piece. That makes the sound seem less natural. You can add very simple and subtle gradient/ value noise on the various part of the program. For example how loud each key is should vary from note to note (usually the choice of the pianist, articulating their vision of the piece). Also you can add the noise to when the notes are played in the measure, how long they are held etc.
That was all, I hope you enjoyed reading! You can follow me on my Twitter: IRCSS
Further Reading
- Designing Sound by Andy Farnell, a book I highly recommend if you wish to read more on procedural sounds and theory of sounds — the physics or psychoacoustics: https://mitpress.mit.edu/books/designing-sound
- Procedural Audio Repo by Konstantinos Sfikas, covering how to do frequency modulation : https://github.com/konsfik/Unity3D-Coding-Examples/blob/7650111bf68f49287317810275db3ffbdae7d65f/3-Procedural-Audio/ProceduralAudioUnityProject/Assets/Scripts/Classes/SinusWave.cs#L26
- Short animation show casing how the piano string is played along with stoppers: https://youtu.be/2kikWX2yOto
- Show casing simple procedural sound usage in games: https://www.gamedeveloper.com/audio/procedural-audio-in-unity
- Sound Envelopes on wikipedia: https://en.wikipedia.org/wiki/Envelope_(music)
- Wikipedia article on the Equal Loudness curvers: https://en.wikipedia.org/wiki/Equal-loudness_contour